


During the past few years, we have seen the rise of a new design pattern within the enterprise data movement solutions for data analytics. This new pattern is called ELT (Extract-Load-Transform) and it complements the traditional ETL (Extract-Transform-Load) design approach. In this post you’ll discover some of the key differences of ETL vs ELT.
Azure Data Factory, as a standalone service or within Azure Synapse Analytics, enables you to use these two design patterns.
Design patterns do not highlight which tools you have to use, but provide guidelines to solve different business problems within the data integration layer.
You don’t have to use only one design pattern for your approach, but you can define one of them as the preferred design approach for your architecture principles.
Keep reading to learn which approach to follow depending on your requirements.
Table of Contents
ETL (Extract-Transform-Load)
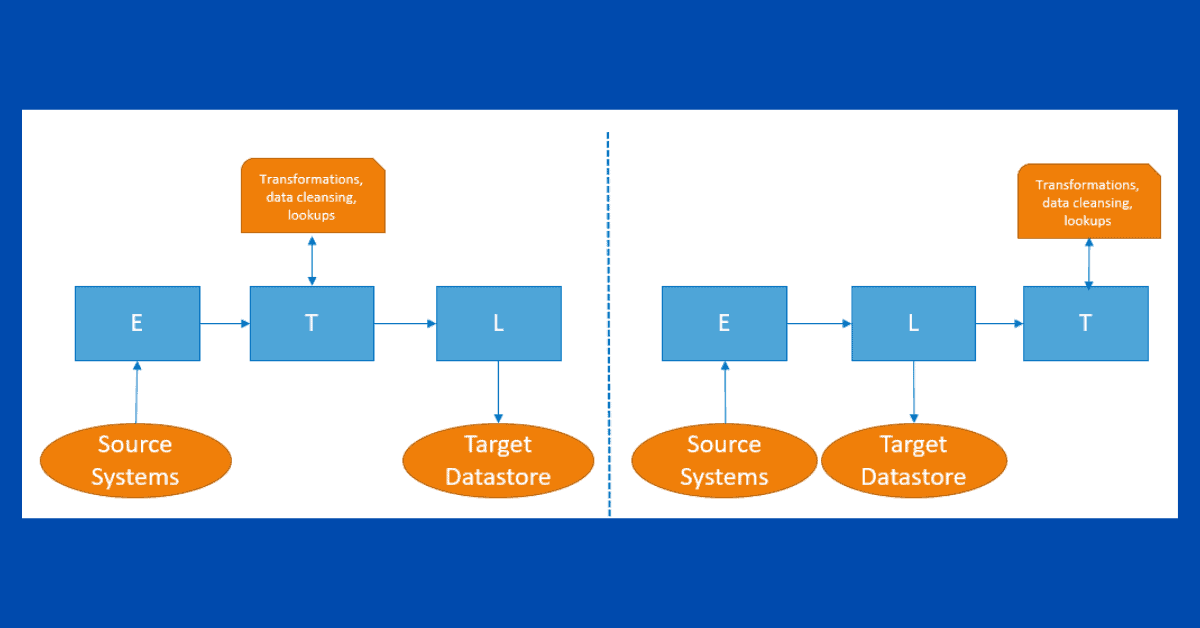
To begin, ETL stands for Extract-Transform-Load. This has been the traditional approach for many years. It requires data to be transformed before being loaded into the target datastore.
This means you need additional compute power to apply these transformations. In the past, many tools on the market had some limitations when transforming large volumes of data (big data) and processes became extremely time-consuming.
However, this problem no longer exists when using Apache Spark or Databricks. Azure Data Factory Mapping Data Flows uses Apache Spark in the backend.

ELT (Extract-Load-Transform)
In contrast, ELT stands for Extract-Load-Transform. The transformations are applied after you have loaded data into the target datastore. This does not necessarily mean that you won’t be using a staging or transient area to apply these transformations.
Recently, this design approach became quite popular. This is because many technology providers offer better performance when using this approach and enable businesses to process any volume of data.
Additionally, it helps to develop a solution that will still be valid for years to come with this approach. This design takes advantage of existing compute power in your target datastore, and no additional computing power is required.
This is the recommended approach when using MPP (massively parallel processing database) systems such as Azure Synapse Analytics or Snowflake.
Using the ELT approach helps relational datastores to take advantage of multi parallelism processing that is already built-in within the data store. It’s the recommended approach for working with Data Lakes because large volumes of data and files can be processed simultaneously.

What are the differences: ETL vs ELT?
The following table describes key differences between the ETL vs ELT design patterns. Some of them rely on findings by using available market tools.
| Concept | ETL (Extract-Transform-Load) | ELT (Extract-Load-Transform) |
| Transformations and Data Cleansing | In transit, before target datastore | In target datastore |
| Business Logic | Hosted in the transformation layer | Hosted in target datastore, it helps you ship the solution to new platforms |
| Investment | Additional investment for the transformation layer and provision compute power. Using ETL tools requires getting additional product licenses | Use of existing compute power in target datastore for transformations, minimizing the number of licenses that need to be bought |
| Volume | Low to medium * | Low to large (big data) |
| Velocity | Slow * | Fast |
| Variety | It supports any type of data asset | It supports any type of data asset |
| Visual Representations (Data Lineage) | Any ETL tool will provide a visual representation of the data lineage and transformations applied | When using the ELT design pattern, a visual representation of the transformations and data lineage is often unavailable |
| Maintainability, Governance, Development | Additional skills are required to use ETL tools. It’s easy to start using them, but becomes difficult when following best practices. These skills could be limited in the market | The orchestration of data movement may happen in a different tool, but transformations are usually applied using SQL. Everybody knows SQL |
* This can be mitigated by using big data tools like Apache Spark or Databricks
ETL Tool Samples
You can implement both design approaches with any tool, but some tools were built on top of the ETL approach. For the following classification, consider this factor.
The following table contains some examples:
| ETL | ELT |
| Azure Data Factory Data Flows SQL Server Integration Services Informatica | Azure Data Factory Activity Pipelines Databricks Apache Spark |
Summary
In summary, you’ve had a look at two of the most important design approaches within enterprise data analytics data movement.
Are you missing any specific characteristics that you’d like me to include? Please leave a comment below.
What’s Next?
During the next few weeks, we will explore more features and services within the Azure offering.
Please follow me on Twitter at TechTalkCorner for more articles, insights, and tech talk!

2 Responses
Ankita Chaturvedi
25 . 05 . 2021I would like to understand when copy command should be preferred over polybase in synapse or ADF. What is best use case for using copy command instead of polybase.
David Alzamendi
27 . 06 . 2021Hi Ankita,
Copy command can have better performance than polybase, you should try to always use the new COPY command.
Regards,
David