Azure Synapse Analytics Data Hub allows you to navigate your data assets using the workspace experience and without writing any code! It includes your SQL Pool databases, Lake databases, Azure Data Lake, Storage Accounts, and other external data like Azure Cosmos DB or Azure Data Explorer.
Table of Contents
Introduction to Azure Synapse Analytics Data Hub
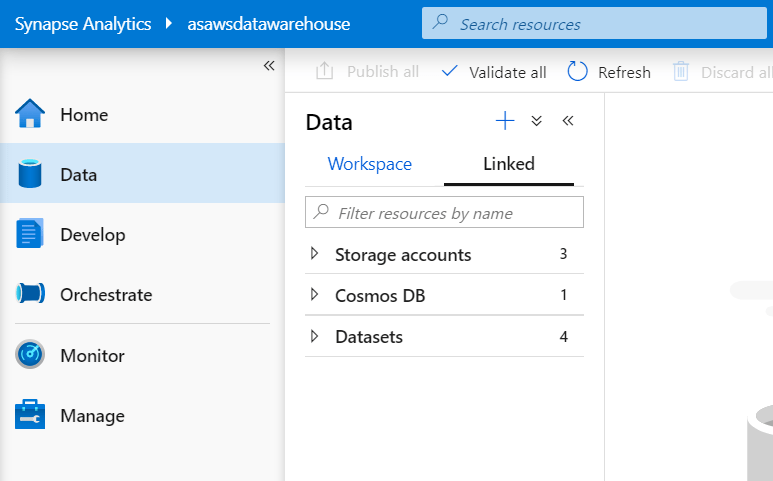
The Data Hub has 2 main sections:
1 – Workspace: with data assets that belong to the Azure Synapse Analytics Workspace. For example:
- Lake database
- SQL Pools
- Apache Spark Pools
2 – Linked: with data assets linked from other services. For example:
- Azure Data Lake
- Storage Accounts
- Cosmos DB
- Datasets
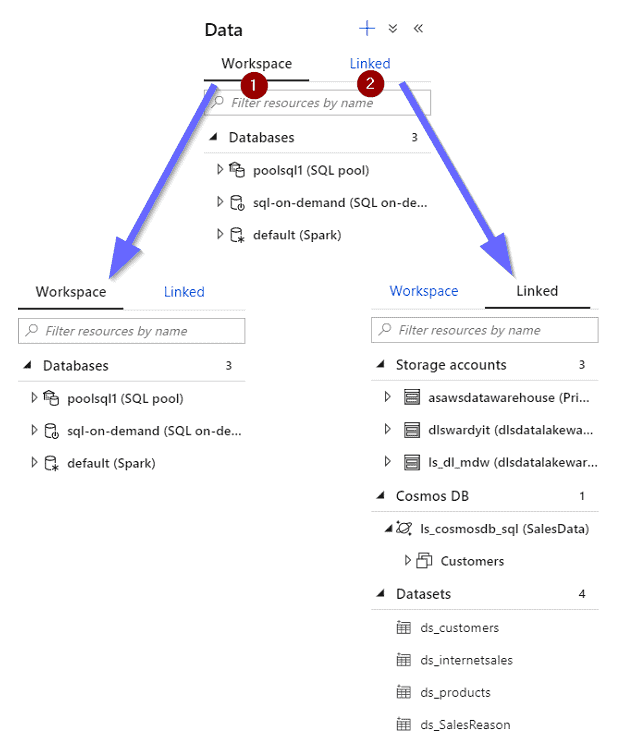
You are able to either link existing services or create datasets (using more than 85 connectors):
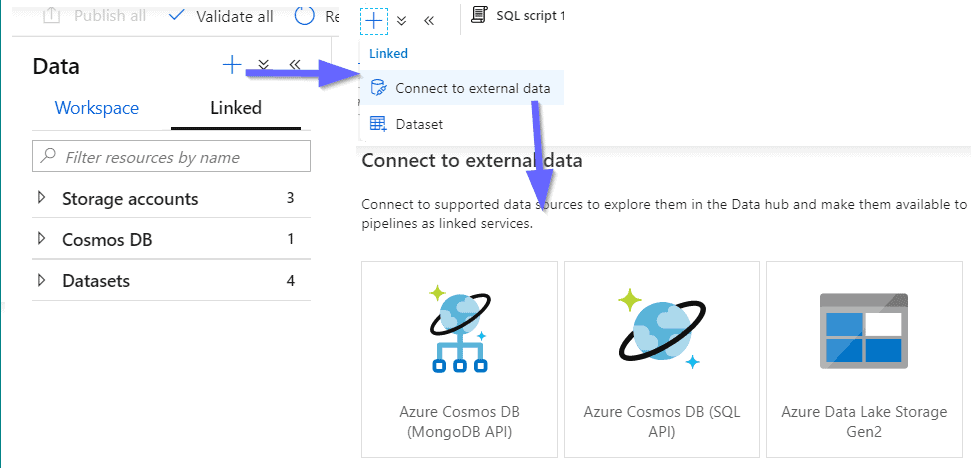
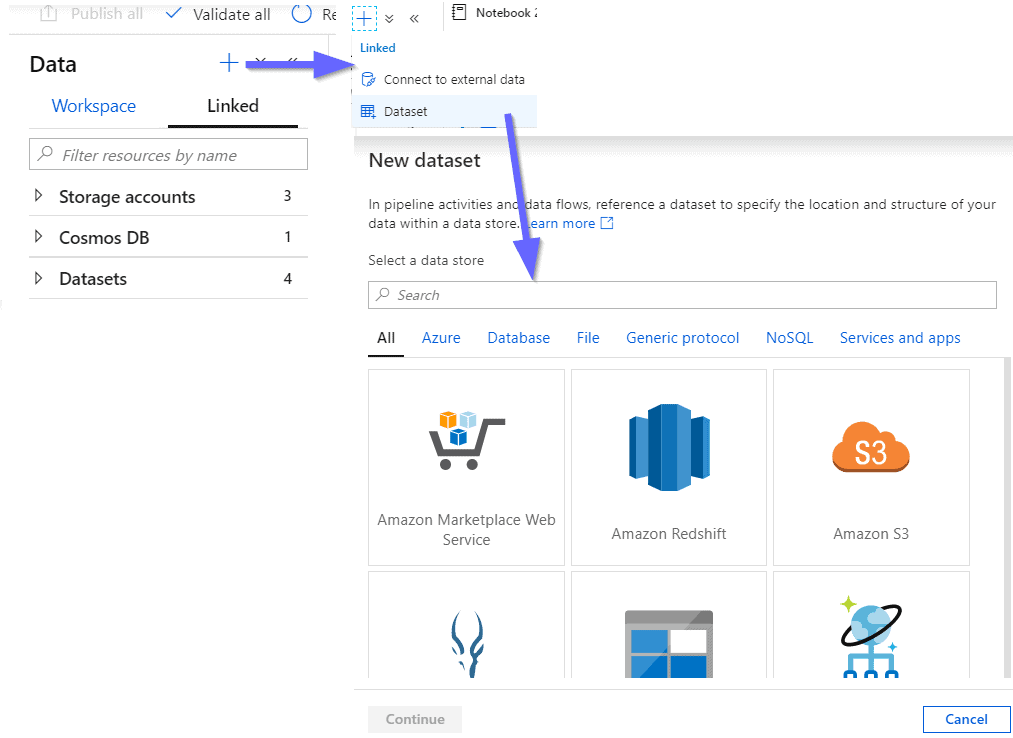
Some of the data sources will be described below.
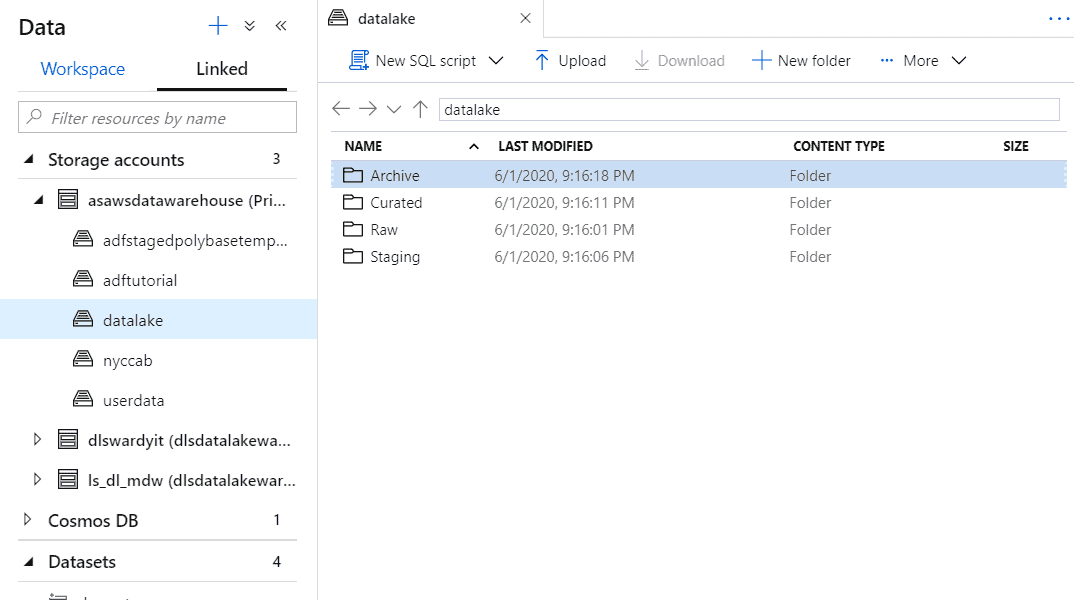
Storage Accounts
In the Storage Accounts, you can link your Azure Data Lake accounts to navigate folders/containers easily. It is similar to the experience in Azure Storage Explorer client tools and web portal. You can upload and download files, as well as create and rename objects.
Let’s explore the user functional features that we have, such as no-code exploring/previewing data, modifying properties and granting access.
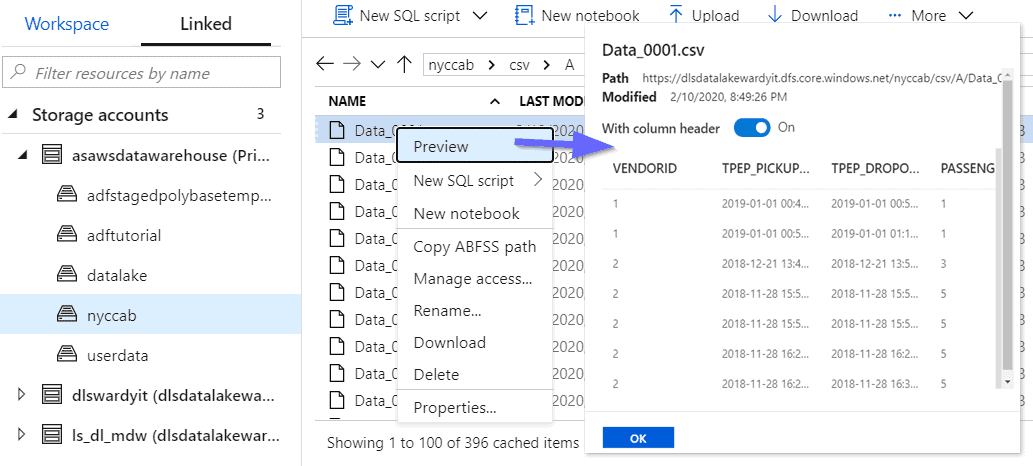
Opening files with SQL Scripts:
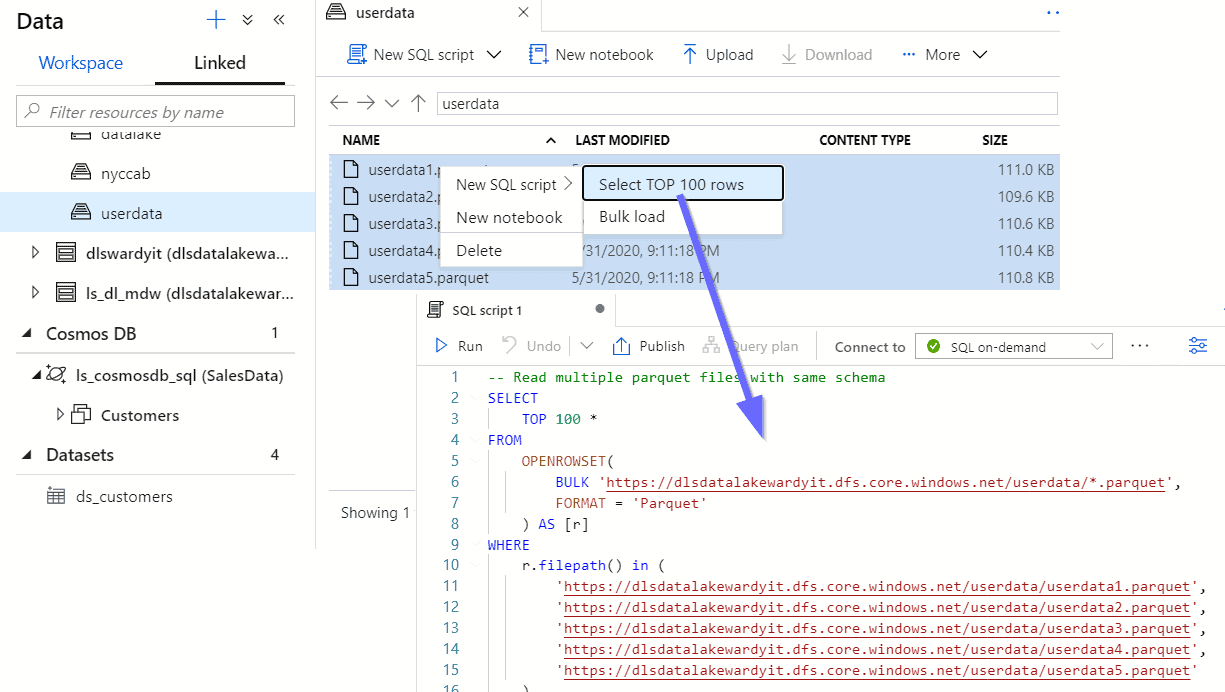
Opening files with notebooks:
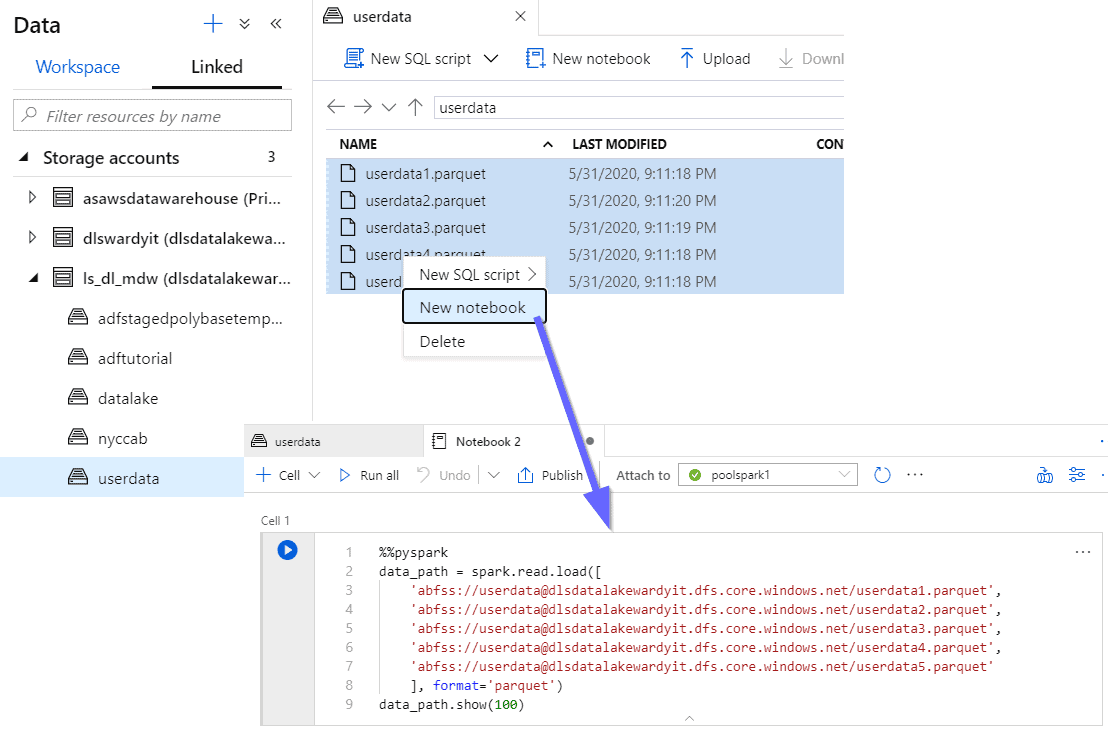
Databases
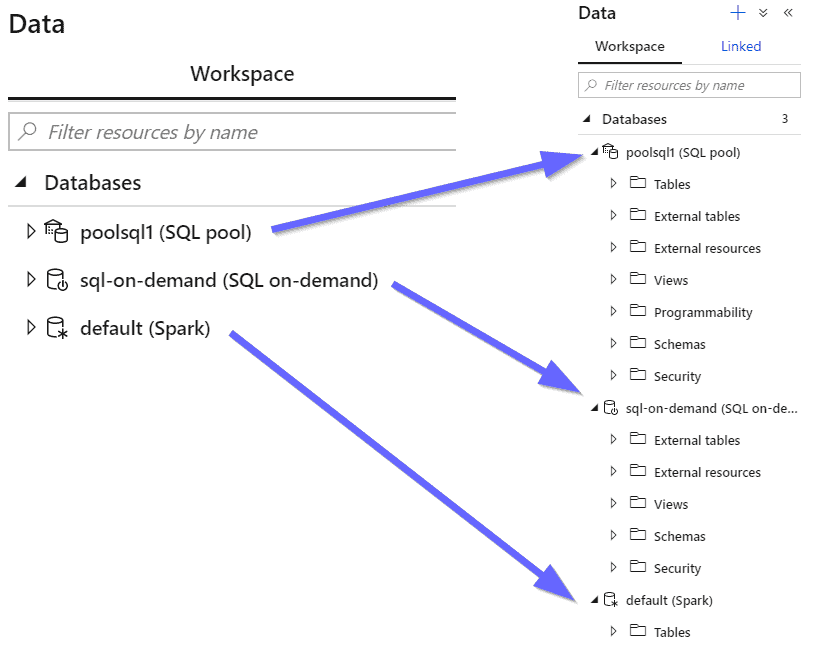
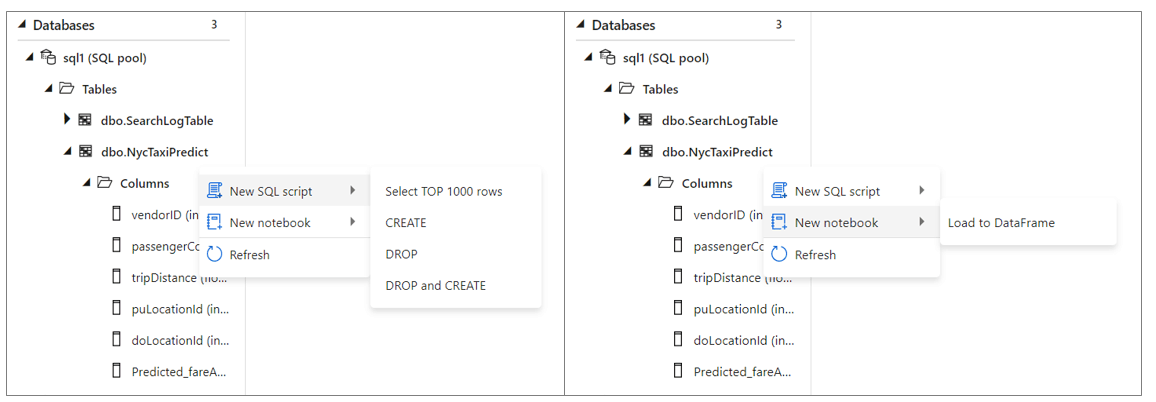
As discussed in a previous post, there are 2 form factors (provisioned and on-demand) and 2 analytics runtimes (SQL and Spark). In the database section, you are allowed to query any of them and use SQL Scripts and Notebooks.
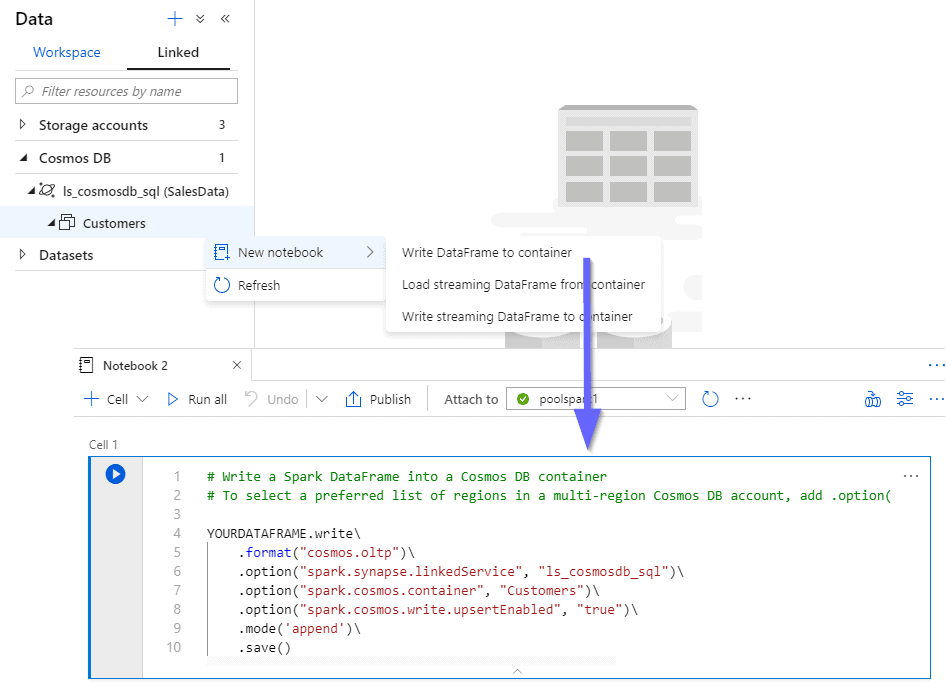
Cosmos DB
You can take advantage of Azure Synapse Analytics Link to consume your Cosmos DB information, bridging the gap between transactional and analytical databases.
Datasets
In the dataset section, you can define the dataset formats using more than 85 connectors in order to use them when developing pipelines. The experience seems to be the same that we currently have in Azure Data factory.

Final Thoughts
It’s clear that the Data Hub offers a no-code experience for the users, enabling them to start exploring data without having a strong technical background. This user-friendly experience is one of the key reasons why I believe Azure Synapse Analytics will be a game-changer.
What’s Next?
In upcoming blog posts, I will be covering the other hubs in more detail.