In this blog post, we’ll cover the main libraries of Apache Spark to understand why having it in Azure Synapse Analytics is an excellent idea. Azure Synapse Analytics brings Data Warehousing and Big Data together, and Apache Spark is a key component within the big data space.
In my previous blog post on Apache Spark, we covered how to create an Apache Spark cluster in Azure Synapse Analytics. Today, let’s check out some of its main components.
Table of Contents
A few facts about Apache Spark
- You can develop solutions writing code in Scala, Python, Spark SQL, .NET or R using language bindings.
- Built to process large volumes of data and to overcome the limitations of MapReduce back in 2009 by Matei Zaharia. The release date for version 1.0 was 2014. Matei Zaharia is one of the co-founders of Databricks (around 2013).
- An open-source platform and it combines batch and real-time (micro-batch) processing within a single platform.
- Azure Synapse Analytics offers version 2.4 (released on 2018-11-02) of Apache Spark, while the latest version is 3.0 (released on 2020-06-08). You can expect to have version 3.0 in Azure Synapse Analytics in the near future.
- Azure Databricks released the use of Apache Spark 3.0 only 10 days after its release (2020-06-18). Technology providers must be on top of the game when it comes to releasing new platforms.
- Azure HDInsight Apache Spark also runs version 2.4. Is it a coincidence? No, Azure Synapse Analytics takes advantage of existing technology built-in HDInsight.
- Apache Spark was built for and is proved to work with environments with over 100 PB (Petabytes) of data.
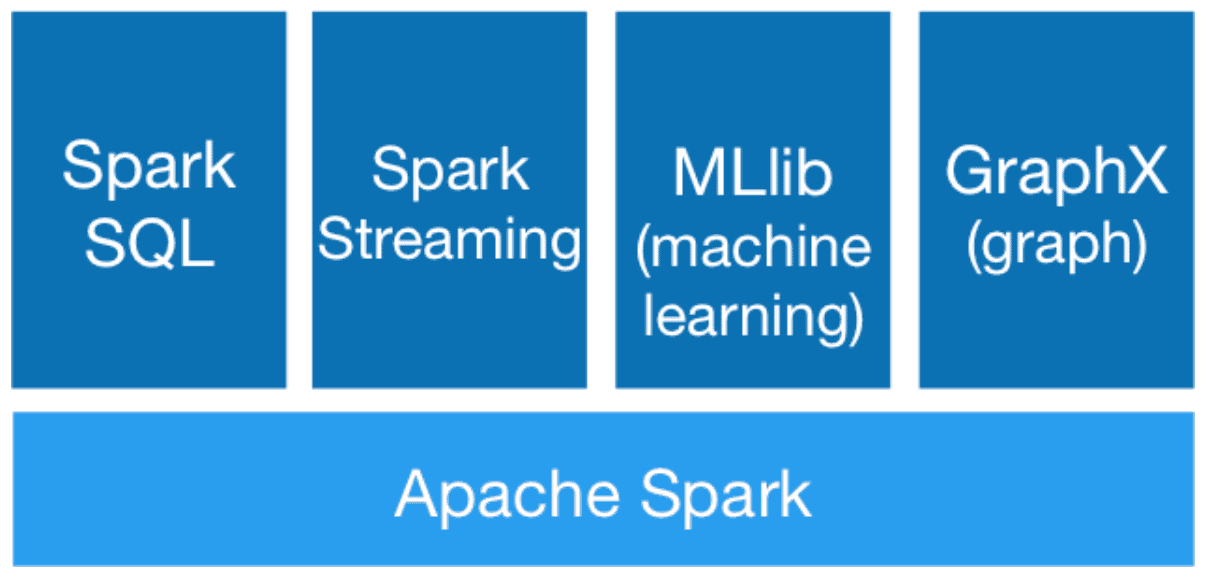
Apache Spark Libraries
You can find 4 main libraries:
- Spark SQL
- Spark Streaming
- MLlib
- GraphX

Spark SQL
I imagine Spark SQL was thought of as a must-have feature when they built the product. Spark SQL allows developers to use SQL to work with structured datasets. It allows you to:
- Perform distributed in-memory computations of large volumes of data using SQL
- Scale your relational databases with big data capabilities by leveraging SQL solutions to create data movements (ETL pipelines). This can be done using non-structured or structured datasets
- Take advantage of existing knowledge in writing queries with SQL
- Integrate relational and procedural programs using data frames and SQL
Additionally,
- Many Business Intelligence (BI) tools offer SQL as an input language by using the JDBC/ODBC connectors. This extends your BI tool to consume big data
- By creating tables, you can easily consume information with Python, Scala, R, and .NET

Spark Streaming
Bringing real-time data streaming within Apache Spark closes the gap between batch and real time-processing by using micro-batches. Before, you usually had different technologies to achieve these scenarios. For example, Hadoop and MapReduce for batch processing and Apache Storm for real-time streaming.
You can stream real-time data and apply transformations with Continuous Processing with end-to-end latencies as low as 1 millisecond.

MLlib (machine learning)
MLlib speeds up data scientists’ experimentations, not only due to the large number of libraries included as part of MLlib, but also because analyzing large volumes of information is time-consuming and Apache Spark can deal with this.
It provides tools such as (the following information comes from Apache Spark documentation):
- ML Algorithms: common learning algorithms such as classification, regression, clustering, and collaborative filtering
- Featurization: feature extraction, transformation, dimensionality reduction, and selection
- Pipelines: tools for constructing, evaluating, and tuning ML Pipelines
- Persistence: saving and loading algorithms, models, and Pipelines
- Utilities: linear algebra, statistics, data handling, etc.
GraphX (graph)
GraphX enables you to perform graph computation using edges and vertices. It is developed and enhanced for each Apache Spark release, bringing new algorithms to the platform.
Running analytical graph analysis can be resource expensive, but with GraphX you’ll have performance gains with the distributed computational engine.
Graph analysis covers specific analytical scenarios and it extends Spark RDDs.

Summary
In this blog post, you looked at some of the components within Apache Spark to understand how it makes Azure Synapse Analytics a game-changing one-stop-shop for analytics and helps develop data warehousing or big data workloads.
Final Thoughts
During the past few years while working in the data analytics space, I’ve seen the rise of big data technologies, with some of the main limitations for their adoption being deployment, maintenance, governance, and anything related to its lifecycle. Having managed clusters in Azure Synapse Analytics or Azure Databricks helps mitigate these limitations.
What’s next?
During the next few weeks, we’ll explore more features and services within the Azure offering.
Please follow me on Twitter at TechTalkCorner for more articles, insights, and tech talk!